
Duże modele językowe z jakich korzystamy na co dzień, jak na przykład ChatGPT, są uruchamiane w chmurze i są zazwyczaj zarządzane przez duże korporacje. Najczęściej nie mamy możliwości pełnej kontroli nad tym jak przetwarzane są nasze zapytania, czy co dzieje się z naszymi danymi. Dane takie mogą być wykorzystywane do uczenia modeli AI, udostępniane podmiotom trzecim, jak również mogą zwyczajnie wyciec do internetu. Dlatego też korzystając z dostępnych usług nie powinno się udostępniać poufnych danych, danych osobowych czy tajemnic firmy. Może to rodzić poważne konsekwencje, z odpowiedzialnością prawną włącznie.
Rozwiązaniem jest uruchomienie modelu językowego lokalnie, czyli na swoim własnym komputerze. Obecnie istnieje bardzo wiele darmowych modeli językowych. Nawet firma OpenAI przedstawiła ostatnio swoje dwa otwarte modele gpt-oss-20b oraz gpt-oss-120b. Inne popularne modele to Mistral, Qwen czy Gemma3.
Wymagania sprzętowe #
Wszystko pięknie i ładnie, ale pewno zastanawiacie się jak potężny trzeba mieć komputer żeby coś takiego uruchomić. Przecież wielkie firmy inwestują miliardy w infrastrukturę, a pojedyncza karta, na przykład H100, kosztuje obecnie około 30 tys. dolarów. Prawdopodobnie nie uda Wam się odpalić największych modeli językowych o wielkości setek miliardów parametrów na swoim komputerze, ale mniejsze modele uruchomicie niemal na każdym sprzęcie. Skoro wspomniałem już o parametrach, to musimy najpierw zrozumieć, co to właściwie jest i jak wpływa na wymagania systemowe.
Obecnie królujące modele sztucznej inteligencji oparte są na sieciach neuronowych. Informacja zapisana jest w tzw. wagach połączeń, czyli w tym jak silne są połączenia między neuronami. Wagi są po prostu liczbami. Na poziomie działania modelu są to zazwyczaj 16-bitowe liczby zmiennoprzecinkowe (FP16 lub BF16), czyli zajmują dwa bajty. Ponadto dla każdego neuronu określa się wartość przesunięcia. Ponieważ neuronów jest bardzo dużo, to i dużo mamy parametrów. Jeżeli model opisany jest na przykład jako 7B, oznacza to, że ma około 7 miliardów parametrów (B oznacza miliardy). Licząc zgrubnie, że każdy parametr potrzebuje 2 bajty pamięci, daje nam to 14 GB danych. Do tego dodatkowe dane, cache, bufory i wychodzimy na ok. 16 GB. A zatem tyle byśmy potrzebowali pamięci, aby uruchomić cały model. Ponadto najlepiej by było gdybyśmy mieli nie tylko dużą pamięć fizyczną RAM, ale także VRAM, czyli pamięć na karcie graficznej (GPU). Wtedy model działałby jeszcze szybciej niż na naszym procesorze CPU. To jednak oznacza, że musielibyśmy mieć całkiem porządną kartę graficzną z dużym rozmiarem pamięci. W przypadku modeli takich jak gpt-oss-20b, który ma około 21 mld. parametrów, rozmiar wymaganej pamięci byłby jeszcze większy.
Dygresja: Tak wiem, mówiłem, że B to miliardy, a tu pomimo zapisu 20B jest 21 mld. parametrów. Wynika to z tego, że opisy są najczęściej zaokrąglane w górę albo w dół, wedle widzimisie twórców. Tak samo gpt-oss-120b nie ma 120 mld. parametrów, tylko 117 mld.
Czy to oznacza, że musimy mieć najnowszy komputer z kartami graficznymi RTX 4. lub 5. generacji? Nie. Ponieważ istnieje coś takiego jak kwantyzacja modelu, czyli możliwość jego zmniejszenia.
Modele skwantyzowane na ratunek #
Jak widzimy modele językowe w swojej pierwotnej postaci potrzebują sporych zasobów pamięci. Gdybyśmy jednak wagi i inne parametry zapisali z użyciem mniejszej liczby bitów, na przykład 8, może 5, albo nawet 4 bitów, zamiast 16, to zaoszczędzilibyśmy sporo pamięci. Proces ten nazywany jest kwantyzacją modelu. Oczywiście im mniej bitów użyjemy tym więcej danych stracimy, a zatem model będzie dawał mniej poprawne odpowiedzi. Niestety, coś za coś. Wróćmy teraz do naszego poprzedniego przykładu. Jeżeli zapisalibyśmy każdy z 7 mld. parametrów przy użyciu jedynie 5 bitów, to potrzebowalibyśmy do tego około 4.3 GB, to znacząco mniej niż poprzednio. W trakcie działania model będzie co prawda potrzebował pamięci na wagi po dekwantyzacji i cache, ale i tak nie powinno to wymagać więcej niż 8 GB. Modele skwantyzowane często oznacza się jako Q8, Q5 lub Q4, zależnie od liczby bitów przeznaczonej na zapisanie pojedynczego parametru.
W poniższej tabeli przedstawione są przybliżone wymagania dotyczące pamięci (RAM/VRAM) dla różnych modeli językowych. Widzimy o ile niższe są wymagania modeli skwantyzowanych, w porównaniu do tych o połowicznej precyzji (ang. half-precision). Są to orientacyjne wartości wynikające z liczby parametrów + narzut około 20%.
| Model | FP16 / BF16 | Model skwantyzowany (Ollama) |
|---|---|---|
| Mistral 7B | ≈ 16.8 GB | ≈ 8.3 GB (Q4_K_M) |
| Gemma 3 1B | 1.6 GB | ~0.8 GB (Q4_0) |
| Gemma 3 4B | 7.7 GB | 3.8–4.1 GB (Q4_0) |
| Gemma 3 12B | 24 GB | 9.8–10.4 GB (Q4_0) |
| Gemma 3 27B | 55.7 GB | ~26.4 GB (QAT, Q4_0) |
| Qwen 7B | ≈ 16.8 GB | ≈ 7.2 GB (Q4) |
| GPT-OSS 20B | ~50.4 GB | ~19.2 GB (MXFP4) |
| GPT-OSS 120B | ~280.8 GB | ~96 GB (MXFP4) |
Jak uruchomić model lokalnie – Ollama #
Istnieje wiele sposobów na uruchomienie lokalnie modelu językowego, jednak jednym z najprostszych jest posłużenie się programem Ollama. Większość modeli dostępnych w programie Ollama jest już skwantyzowanych, a co za tym idzie mają dużo mniejsze wymagania sprzętowe niż pełne modele.
Ponadto Ollama radzi sobie doskonale z wykorzystaniem zarówno procesora (CPU), jak i karty graficznej (GPU). Nawet jeżeli nie posiadamy odpowiedniej karty graficznej, to model zostanie w pełni uruchomiony na CPU. W takim przypadku należy mieć jednak świadomość, że będzie działał znacznie wolniej niż z wykorzystaniem GPU. Jeżeli jednak posiadamy odpowiednią kartę graficzną, to Ollama rozdzieli obliczenia pomiędzy CPU i GPU, a wszystko będzie się działo automatycznie.
Całą procedura uruchomienia to tylko kilka kroków:
-
Należy pobrać program Ollama z oficjalnej strony Ollama.com. W przypadku Windowsa pobieramy instalator i go uruchamiamy, dla Mac OS mamy plik DMG, a w przypadku Linuxa korzystamy z polecenia curl (opis na stronie).
-
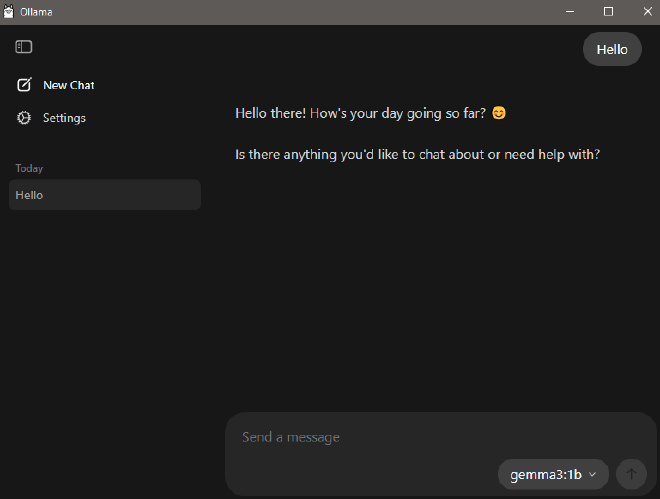
Gdy już zainstalujemy i uruchomimy program naszym oczom ukaże się prosty interfejs widoczny na poniższym obrazku. Z prawej strony mamy menu rozwijane, w którym wybieramy model. Najlepiej jest zacząć od modeli, które mają małą liczbę parametrów np. 1B, 4B i zobaczyć czy działają one odpowiednio szybko. Potem ewentualnie można przejść do modeli o większej liczbie parametrów.

- Następnie wpisujemy nasze zapytanie i wciskamy ENTER albo klikamy w strzałkę wskazującą do góry. Gdy używamy danego modelu po raz pierwszy, to musi on zostać najpierw pobrany na komputer. Może to zająć kilka do kilkunastu minut, zależnie od wielkości modelu i prędkości pobierania danych z internetu.
Mamy już działający lokalnie model. Teraz jeszcze tylko kilka słów o interfejsie i ustawieniach.
Gdy klikniemy w ikonę w lewym górnym rogu pojawi nam się lista naszych rozmów, jak również ustawienia (ang. Settings)
Gdy klikniemy w ustawienia zobaczymy następujące okno:
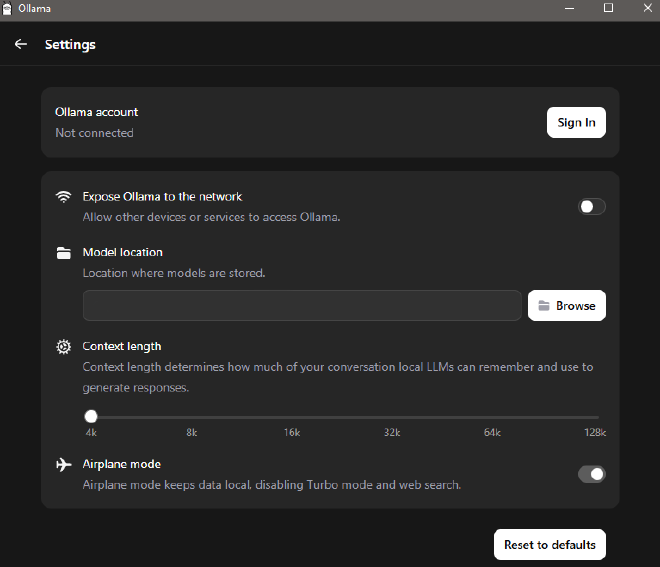
Mamy tam następujące ustawienia:
-
Expose Ollama to the Network – gdybyśmy chcieli, aby nasz model był wystawiony w sieci. Włączenie tego ustawienia oznaczać będzie, że wszystkie urządzenia w danej sieci będą miały dostęp do programu Ollama, będą mogły wysyłać zapytania itd. Domyślnie opcja ta jest wyłączona i ze względów bezpieczeństwa lepiej tak ją pozostawić. Nie ruszać. No chyba, że naprawdę wiecie co robicie.
-
Model location – folder, w którym będą instalowane nowe modele. Najlepiej wybrać folder na dysku, który ma dużo wolnego miejsca i jest dyskiem SSD.
-
Context length – rozmiar okna kontekstowego. Można rozpocząć od domyślnej wartości 4k, ewentualnie nieznacznie zwiększyć w razie potrzeby. Okno kontekstowe mówi o tym, jak wiele informacji model jest w stanie przetworzyć na raz. Jeżeli chcecie operować na danych o dużych rozmiarach, pisać bardzo długie zapytania, to trzeba by zwiększyć rozmiar okna kontekstowego. Do normalnej rozmowy 4k czy 8k na początek wystarczy. Zbytnie zwiększanie okna kontekstowego spowoduje spowolnienie odpowiedzi i wzrost zapotrzebowania na pamięć.
-
Airplane mode – jeżeli nie chcecie korzystać z dostępu do sieci oraz opcji Turbo, czyli przetwarzania zapytania na zewnętrznych serwerach, to możecie włączyć tę opcję. Zresztą nie ma to większego znaczenia, bo najpierw trzeba założyć konto żeby z tych opcji skorzystać, ale dla Waszego spokoju możecie to włączyć.
Więcej modeli #
Chociaż liczba modeli dostępnych w menu kontekstowym jest bardzo ograniczona, to program Ollama wspiera ich bardzo wiele. Pełną listę modeli można zobaczyć na stronie https://ollama.com/search.
W celu skorzystania, z któregoś z tych modeli należy otworzyć konsolę (np. cmd.exe w Windows) i wpisać polecenie:
ollama run nazwa_modelu
Na przykład, dla modelu Mistral 7B wpisujemy:
1ollama run mistral:7b
Uwaga: w trakcie wpisywania polecenia program Ollama musi być uruchomiony, ponieważ wystawia on lokalny serwer. Nie należy się tego obawiać, gdyż serwer dostępny jest tylko z poziomu Waszego komputera. Najczęściej jest to usługa pod adresem localhost:11434.
Po wpisaniu polecenia nastąpi pobranie modelu na dysk, a w programie Ollama w menu pojawi się nowa pozycja.
Podsumowanie #
Reasumując. Macie teraz lokalnie działający model językowy. Wasze zapytania i dane przetwarzane są wyłącznie na Waszym komputerze (chyba, że zaczniecie korzystać z opcji Turbo!). Gratulacje. Kolejny etap to fine-tuning, korzystanie z API i zabawa parametrami modelu, ale to już temat na kolejny artykuł.